
Charles Feng, Mohammed Mogasbe, Justin Berman, Bruno Fantauzzi
If you're integrating AI assistants into your product, you've probably discovered that maintaining parallel implementations for REST APIs and MCP servers leads to subtle inconsistencies that only surface in production.
We found a better way at StockApp: we use our existing ts-rest API contracts to automatically expose MCP tools alongside our REST endpoints in the same server. Both interfaces directly call the same route handler functions, ensuring they share the exact same implementation, authorization logic, and validation rules.
At a startup, this means shipping AI features in minutes instead of days with the confidence they're production-ready. At scale, it helps many engineers operate more consistently and eliminates an entire category of bugs – there's no drift between your REST API and tools exposed via MCP because they literally run the same code.
🚀 Try it yourself: We've built a complete working example demonstrating this pattern. Clone the sample app to see it in action with a task management API, or keep reading to understand the architecture.
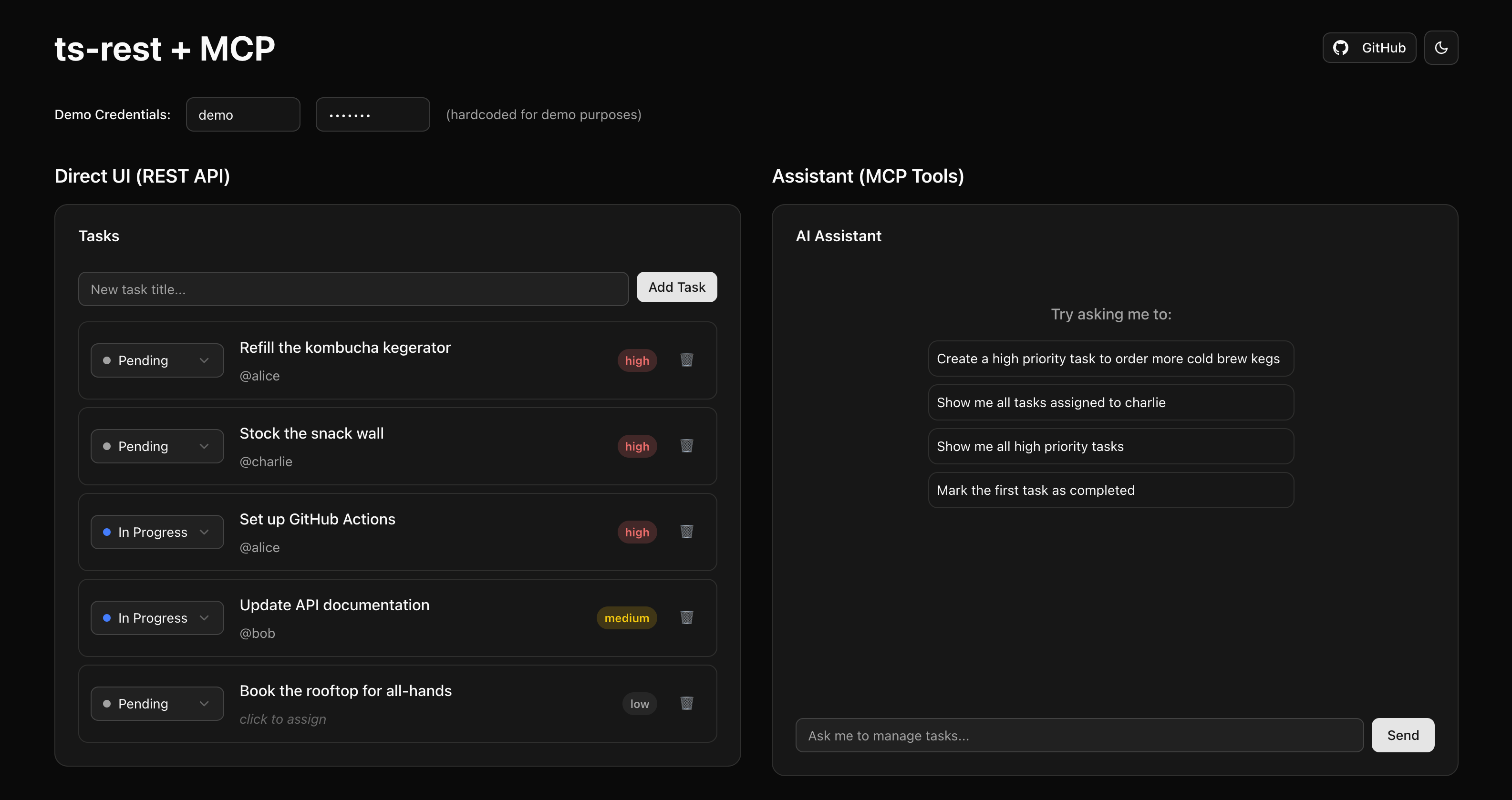
Our sample app showing the same task management API exposed through both REST (left panel) and MCP tools (right panel)
❤️ Want to work at StockApp? We're hiring for all engineering roles.
Why MCP Servers Matter
Releasing an MCP server transforms how customers interact with your product. When you expose your API through MCP, customers can use Claude Desktop, Claude Code, or any MCP-compatible assistant to work with your platform in natural language. Emergent workflows become possible when your tools are combined with others in their MCP ecosystem.
Internally, MCP standardizes your AI assistant architecture. Instead of building custom integrations for each AI framework, you have one interface that works with Claude, Mastra, LangGraph, and other tools. Your team can experiment with different AI providers without rewriting integration code.
The Problem with Manual MCP Integration
Most MCP servers are thin wrappers that make HTTP calls to REST APIs. They receive tool calls, transform parameters, make HTTP requests, and return responses. This creates extra latency and maintenance overhead.
Teams typically take one of two approaches:
Approach 1: Duplicate Implementation
Write REST endpoints for your frontend, then write separate MCP tool handlers that reimplement the same logic. This creates obvious maintenance nightmares with diverging business logic, inconsistent validation, and security gaps.
Approach 2: Manual Wrapper Layer
Build MCP tools that call your REST API, but manually define each tool's schema, write parameter transformation code, handle authentication forwarding, maintain error mapping, and keep guidance strings updated.
You end up with hundreds of lines of boilerplate that looks like this:
// Manual MCP wrapper for every single endpoint
mcpServer.registerTool('get_tasks', {
description: 'Get list of tasks',
// Manually maintained guidance that drifts from actual API behavior
guidance: 'Use status filter for task states. Returns max 10 items.',
schema: {
// Manual schema definition that can drift from API
task_status: { type: 'string', enum: ['todo', 'doing', 'done'] },
max_results: { type: 'number', default: 10 }
},
handler: async (params) => {
// Manually reconstruct the API call
const response = await fetch(`${API_URL}/tasks`, {
method: 'GET',
headers: {
'Authorization': `Bearer ${params.auth_token}`,
'Content-Type': 'application/json'
},
// Manual parameter mapping
query: {
status: params.task_status, // Different naming
limit: params.max_results || 20, // Wait, docs say 10?
assignee_id: params.assigned_user // More naming mismatches
}
})
// Manual error handling
if (!response.ok) {
if (response.status === 401) {
throw new Error('Authentication failed')
}
// More manual error mapping...
}
// Manual response transformation
const data = await response.json()
return {
tasks: data.items, // Different structure
total: data.pagination.total_count
}
}
})
This wrapper layer becomes another codebase to maintain. Plus, every MCP tool call makes an HTTP request to your API, adding network latency and requiring authentication forwarding.
When you add a new parameter to your API, you have to remember to update the MCP wrapper. When you change response formats, the wrapper needs updating. When you add new validation rules, they might not make it to the MCP layer. It's essentially maintaining two API contracts that can drift apart.
How ts-rest Changes the Game
We were already using ts-rest for our API contracts. ts-rest defines contracts separately from implementation (unlike tRPC where they're coupled), creating an abstraction layer that decouples your API definition from any specific framework. This separation makes it perfect for serving multiple consumers (REST clients, OpenAPI generators, and as we discovered, MCP tools) from a single source of truth.
Each contract uses Zod schemas that provide runtime validation and TypeScript types. When a request comes in – whether from a REST client or MCP tool – the same Zod schema validates it. This guarantees both interfaces have identical validation rules, not just matching type definitions.
import { initContract } from "@ts-rest/core"
import { z } from "zod"
const c = initContract()
// One schema used everywhere
const TaskSchema = z.object({
id: z.string().uuid(),
title: z.string().min(1).max(200),
description: z.string().max(1000).optional(),
status: z.enum(["pending", "in_progress", "completed"]),
priority: z.enum(["low", "medium", "high"]).default("medium"),
assigned_to: z.string().optional(),
created_at: z.string().datetime(),
updated_at: z.string().datetime(),
completed_at: z.string().datetime().optional()
})
// TypeScript type derived from schema
type Task = z.infer<typeof TaskSchema>
// ts-rest contract leverages schemas for validation and type safety
export const tasksContract = c.router({
listTasks: {
method: "GET",
path: "/tasks",
query: z.object({
status: TaskSchema.shape.status.optional(),
assigned_to: TaskSchema.shape.assigned_to.optional(),
limit: z.coerce.number().positive().max(100).default(20),
offset: z.coerce.number().nonnegative().default(0),
}),
responses: {
200: z.object({
tasks: z.array(TaskSchema),
total: z.number(),
limit: z.number(),
offset: z.number(),
}),
401: UnauthorizedSchema,
},
summary: "List all tasks with optional filtering",
}
})
The contract serves as a single source of truth for the API's shape. Both the server implementation and client code reference this contract, ensuring they stay in sync.
This gives us a type-safe client in our React and Next.js apps:
// Frontend usage with ts-rest client
const apiClient = initClient(tasksContract, {
baseUrl: API_URL,
baseHeaders: {
Authorization: authHeader,
"Content-Type": "application/json",
},
})
// Type-safe API calls
const result = await apiClient.listTasks({
query: { status: "pending", limit: 20 }
})
if (result.status === 200) {
setTasks(result.body.tasks)
}
Plus, ts-rest generates OpenAPI specs that we feed into Stainless to auto-generate SDKs for customers who want to integrate with our platform.
When building our AI assistant, we realized we could extend this pattern further.
Designing APIs for AI Consumption
Traditional REST APIs often accumulate dozens of query parameters over time, many with cryptic names that made sense to the original developer but confuse both humans and AI. Consider an endpoint with parameters like flt_cst_id, inc_arch, grp_by_vnd, and agg_mode – an LLM has to guess what these mean from context, often incorrectly.
Good API design for humans turns out to be good API design for AI. When you use semantic, self-documenting parameter names (customer_id instead of cst_id), group related parameters into logical objects, and provide clear enums for valid values, you're making your API more accessible to both developers and AI assistants. The same thoughtful design that helps a new developer understand your API helps an LLM use it correctly.
This is where ts-rest and Zod shine – they encourage you to define clear schemas with proper validation, meaningful names, and good defaults. Your time_range parameter can be an enum of human-readable options like "last_30_days" rather than cryptic codes. Complex filtering can be simplified with a natural language search or query parameter that your backend interprets, rather than exposing dozens of filter flags.
Adding MCP Metadata to Contracts
By adding a simple metadata field to our contracts, we mark which endpoints should also be exposed as MCP tools:
export const tasksContract = c.router({
listTasks: {
method: "GET",
path: "/tasks",
query: z.object({
status: TaskSchema.shape.status.optional(),
priority: TaskSchema.shape.priority.optional(),
assigned_to: z.string().optional(),
limit: z.coerce.number().positive().max(100).default(20),
offset: z.coerce.number().nonnegative().default(0),
}),
responses: {
200: z.object({
tasks: z.array(TaskSchema),
total: z.number(),
limit: z.number(),
offset: z.number(),
}),
401: ErrorSchema,
},
summary: "List all tasks with optional filtering",
metadata: {
mcp: true,
guidance: `Use this to retrieve tasks.
Filter by status when user asks for specific task states (pending, in progress, completed).
Filter by priority when user asks for important/urgent tasks.
Use pagination with limit and offset for large result sets.`
}
}
})
The metadata serves two purposes. First, the mcp: true flag tells our system to expose this endpoint as an MCP tool. Second, the guidance helps AI assistants understand when and how to use the tool effectively, providing context that goes beyond what a simple function signature conveys.
MCP Tool Registration
When our server starts, it scans all contracts and registers each endpoint as its own MCP tool. This happens once at initialization, so there's no runtime performance impact:
class ToolCache {
private static discoverToolsFromContracts(): McpToolDefinition[] {
const tools: McpToolDefinition[] = []
// Iterate through contracts (tasks, etc.)
for (const [contractName, contractRouter] of Object.entries(contractMap)) {
// Iterate through endpoints in each contract (listTasks, createTask, etc.)
for (const [endpointName, endpoint] of Object.entries(contractRouter)) {
// Only register endpoints with mcp metadata set to true
if (!endpoint.metadata?.mcp) continue
const toolName = `${contractName}_${endpointName}`
.replace(/([A-Z])/g, "_$1")
.toLowerCase()
const inputSchema = this.createInputSchema(endpoint)
tools.push({
name: toolName,
description: endpoint.summary,
guidance: endpoint.metadata?.guidance,
inputSchema,
contractPath: [contractName, endpointName],
endpoint,
})
}
}
return tools
}
private static createInputSchema(endpoint: any) {
const schema: any = {}
// Add path parameters
if (endpoint.pathParams?.shape) {
Object.assign(schema, endpoint.pathParams.shape)
}
// Add body parameters
if (endpoint.body?.shape) {
Object.assign(schema, endpoint.body.shape)
}
// Add query parameters
if (endpoint.query?.shape) {
Object.assign(schema, endpoint.query.shape)
}
return schema
}
}
With the tools discovered, we register each one individually:
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js"
export class ToolRegistrar {
constructor(private routeInvoker: RouteInvoker) {}
registerAllTools(server: McpServer) {
const toolDefinitions = ToolCache.getToolDefinitions()
for (const toolDef of toolDefinitions) {
server.registerTool(
toolDef.name, // e.g., "tasks_list_tasks", "tasks_create_task"
{
description: toolDef.description,
inputSchema: toolDef.inputSchema,
},
async (params, extra) =>
this.routeInvoker.invokeRoute(toolDef.contractPath, toolDef.endpoint, params, extra)
)
}
}
}
export class RouteInvoker {
async invokeRoute(contractPath: string[], endpoint: any, mcpParams: any, extra: any) {
// Get the route implementation
const routeFunction = this.getRouteFunction(contractPath)
// Transform MCP's flat parameters to REST's structured format
const params: any = {}
const query: any = {}
const body: any = {}
// Get parameter definitions from endpoint
const pathParamKeys = endpoint.pathParams?.shape ? Object.keys(endpoint.pathParams.shape) : []
const queryKeys = endpoint.query?.shape ? Object.keys(endpoint.query.shape) : []
const bodyKeys = endpoint.body?.shape ? Object.keys(endpoint.body.shape) : []
// Distribute parameters to correct locations
for (const [key, value] of Object.entries(mcpParams)) {
if (pathParamKeys.includes(key)) {
params[key] = value
} else if (queryKeys.includes(key)) {
query[key] = value
} else if (bodyKeys.includes(key)) {
body[key] = value
}
}
// Call the route function directly
const routeResponse = await routeFunction({
params,
query,
body: Object.keys(body).length > 0 ? body : undefined,
req: {
headers: extra?.requestInfo?.headers || {},
...extra?.authInfo?.req,
},
})
// Format route response to MCP format
return {
content: [{
type: "text",
text: JSON.stringify(routeResponse.body, null, 2),
}],
}
}
}
Every endpoint marked with mcp: true in your contracts is now available as its own MCP tool. In Claude or other AI assistants, you can directly call tool("tasks_list_tasks", {status: "pending"}) without needing to discover tools first.
Alternative: Dynamic Tool Discovery
When you have tens of endpoints, registering each one as a separate MCP tool can overwhelm AI assistants. An alternative is to use a dynamic discovery pattern with just two tools:
// Instead of registering each endpoint, provide discovery tools
mcpServer.registerTool('list_tools', {
description: 'List available API tools',
inputSchema: {
type: 'object',
properties: {
filter: { type: 'string', description: 'Optional filter for tool names' }
}
}
}, async ({ filter }) => {
const tools = ToolCache.getToolDefinitions()
const filtered = filter
? tools.filter(t => t.name.includes(filter))
: tools
return {
content: [{
type: 'text',
text: JSON.stringify(filtered.map(t => ({
name: t.name,
description: t.description
})))
}]
}
})
mcpServer.registerTool('call_tool', {
description: 'Call a specific API tool',
inputSchema: {
type: 'object',
properties: {
name: { type: 'string', description: 'Tool name from list_tools' },
arguments: { type: 'object', description: 'Tool arguments' }
},
required: ['name', 'arguments']
}
}, async ({ name, arguments: args }, extra) => {
const tool = ToolCache.getToolDefinitions().find(t => t.name === name)
if (!tool) throw new Error(`Tool ${name} not found`)
return invokeRoute(tool.contractPath, tool.endpoint, args, extra)
})
This approach reduces the initial tool list but requires two calls: first to discover available tools, then to invoke them. It's better suited for APIs with hundreds of endpoints where the full list would be overwhelming.
Unified Route Implementation
Both the MCP server and REST API run in the same Node.js process and share route handlers:
// Single implementation handles both REST and MCP
export const listTasks: AppRouteImplementation<typeof tasksContract.listTasks> = async ({ query, req }) => {
// This auth check runs for both REST API calls AND MCP tool invocations
const authError = await checkAuth(req as any)
if (authError) return authError
const tasks = await db.findAllTasks({
status: query?.status,
assigned_to: query?.assigned_to,
limit: query?.limit || 20,
})
return {
status: 200 as const,
body: {
tasks,
total: tasks.length,
limit: query?.limit || 20,
offset: query?.offset || 0,
},
}
}
// REST wires up all routes through contractMap and routeMap
export const contractMap = {
tasks: tasksContract,
users: usersContract,
// ... other contracts
}
export const routeMap = {
tasks: tasksRoutes, // Object with getTasks, createTask, etc.
users: usersRoutes,
// ... other route modules
}
// ts-rest creates the router from contracts and routes
const s = initServer()
export const router = s.router(contract, routeMap)
// MCP automatically discovers and uses the same route implementations!
Because both REST and MCP call the same getTasks function (discovered automatically from the contract), they share all the same authorization checks, business logic, and database optimizations. No HTTP calls between MCP and your business logic means better performance when chaining multiple tools.
Bonus: Dynamic MCP Tools in Your AI Agents
When building AI assistants, you can use Mastra to dynamically load MCP tools with user-specific authentication:
// app/api/chat/route.ts - AI assistant endpoint
import { openai } from "@ai-sdk/openai"
import { Agent } from "@mastra/core/agent"
import { RuntimeContext } from "@mastra/core/di"
import { MCPClient } from "@mastra/mcp"
// Create dynamic MCP client with user's auth
function createTaskServiceMCPClient(runtimeContext: RuntimeContext) {
const authHeader = runtimeContext.get("authHeader")
const serverUrl = process.env.NEXT_PUBLIC_SERVER_URL || "http://localhost:1337"
return new MCPClient({
id: "task-service-dynamic",
servers: {
tasks: {
url: new URL(`${serverUrl}/mcp`),
requestInit: {
headers: {
Authorization: authHeader,
},
},
timeout: 30000,
},
},
})
}
// Create agent with dynamic MCP tools
const createTaskAssistantAgent = () =>
new Agent({
id: "taskAssistant",
name: "Task Assistant",
instructions: `You are a helpful task management assistant.
When users ask you to perform task operations, use the available tools.
Be concise in your responses and confirm what actions you've taken.`,
model: openai("gpt-4o-mini"),
tools: async ({ runtimeContext }) => {
// Add MCP tools dynamically based on user auth
const authHeader = runtimeContext?.get("authHeader")
if (authHeader) {
try {
const mcpClient = createTaskServiceMCPClient(runtimeContext)
const mcpTools = await mcpClient.getTools()
return mcpTools
} catch (error) {
console.warn("Failed to load MCP tools:", error)
return {}
}
}
return {} // No tools without auth
},
})
// Use in your API endpoint
export async function POST(request: NextRequest) {
const { message, authHeader } = await request.json()
// Create runtime context with auth credentials
const runtimeContext = new RuntimeContext()
runtimeContext.set("authHeader", authHeader)
// Execute agent with runtime context
const agent = createTaskAssistantAgent()
const result = await agent.generate(message, { runtimeContext })
return NextResponse.json({ message: result.text })
}
This pattern allows each user's AI assistant to connect to your MCP server with their specific credentials, ensuring proper authorization while reusing all the same tool implementations.
What This Pattern Actually Prevents
Beyond avoiding duplicate code, this pattern prevents the subtle inconsistencies that slow down development.
Permission Drift
When you update REST API permissions, the MCP tools automatically get the same updates since both interfaces execute the same authorization checks:
const checkAuth = async (req, options) => {
const auth = await validateCredentials(req.headers.authorization)
if (!auth.valid) return { status: 401, body: { error: "Invalid credentials" } }
// Check workspace membership
if (options.workspace) {
const isMember = await db.workspaceMembers.exists({
workspace_id: options.workspace,
user_id: auth.userId
})
if (!isMember) return { status: 403, body: { error: "Not a workspace member" } }
}
req.userId = auth.userId
return null
}
Data Consistency Issues
Different interfaces often handle edge cases differently - REST might return null for missing fields while an MCP wrapper throws an error. With one implementation, you get consistent behavior across both interfaces.
Rate Limiting Gaps
AI assistants can generate hundreds of requests quickly if they get stuck in a loop. When both interfaces share the same code path, your existing rate limits apply automatically - no separate configuration needed.
Schema Evolution Overhead
Adding fields, updating validation, or changing response formats typically requires updating multiple implementations. With this pattern, you evolve your API once and both interfaces get the update.
See It In Action
We've built a complete working example that demonstrates this pattern. The sample app shows a task management API with both REST and MCP interfaces running from the same codebase.
The demo UI demonstrates how both interfaces work together:
- Left panel: Direct REST API interaction using a type-safe ts-rest client - you can create, update, and manage tasks through traditional UI controls
- Right panel: AI assistant using MCP tools to perform the same operations through natural language
- Real-time sync: Changes from either side appear instantly because both use the same route handlers and in-memory database
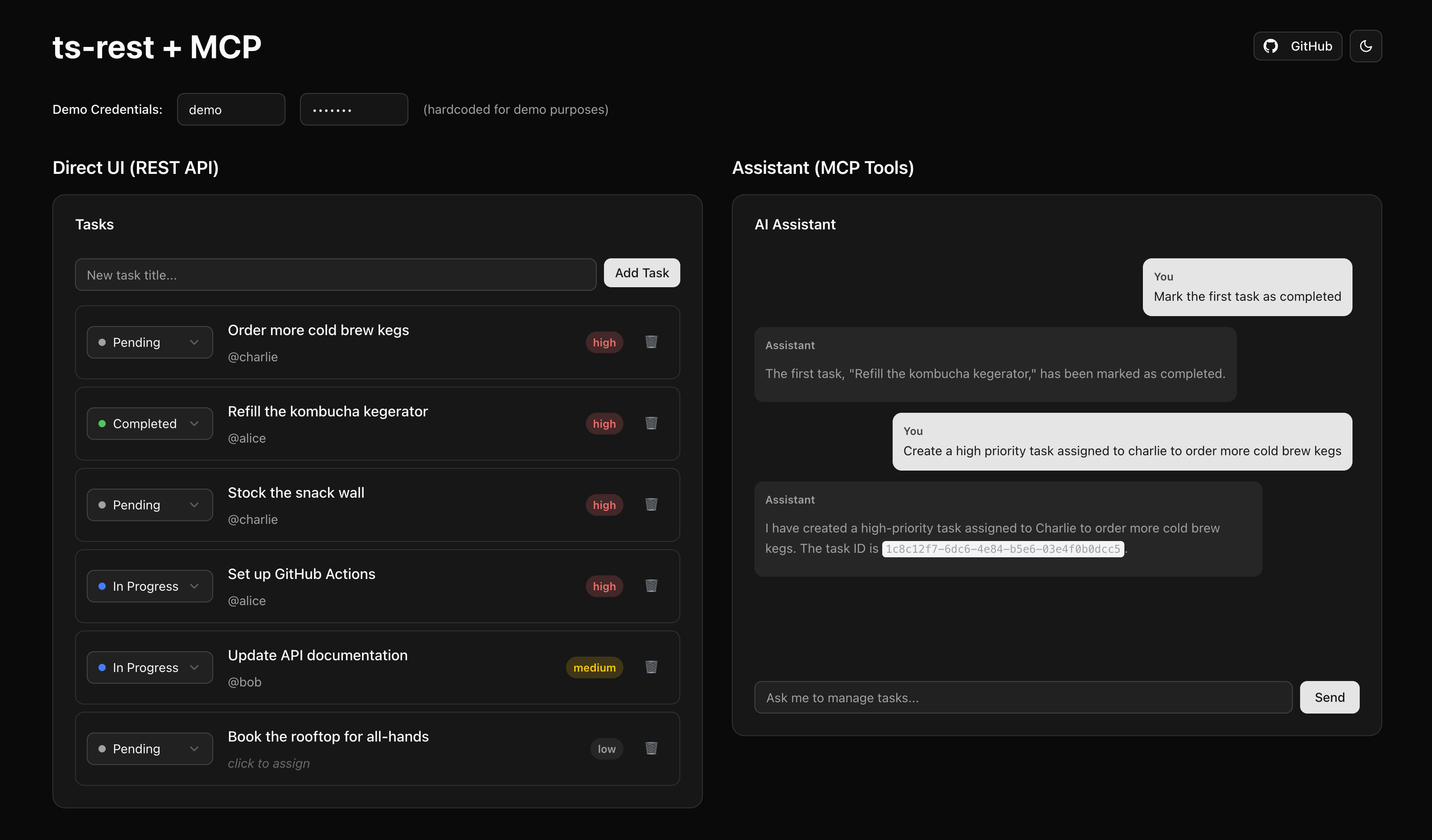
The AI assistant marking tasks as completed and creating new high-priority tasks - all changes instantly reflected in the REST UI
Quick Start
# 1. Clone and install
git clone https://github.com/stockapp-dev/ts-rest-mcp-sample-app
cd ts-rest-mcp-sample-app
npm install
# 2. Add your OpenAI API key
cp client/.env.example client/.env.local
# Edit client/.env.local and add: OPENAI_API_KEY=sk-proj-your-key-here
# 3. Start everything
npm run dev
# 4. Open the demo
open http://localhost:1336
The sample includes:
- Six task management endpoints (list, get, create, update, delete, search)
- Demo authentication that works for both REST and MCP (username: demo, password: demo123)
- Type-safe ts-rest client using shared contracts
- AI assistant powered by Mastra and OpenAI
- OpenAPI documentation auto-generated from contracts
- Example prompts to demonstrate natural language task management
Future Possibilities
This pattern opens up interesting architectural possibilities:
Capability-Based Tool Exposure: We're exploring using JWT scopes or permissions to dynamically determine which MCP tools are available to an AI assistant. A customer support assistant might only get read-only tools, while an admin assistant gets full CRUD operations.
Usage Analytics: Since all AI operations flow through the same code path as regular API calls, we can track how AI assistants use our APIs compared to human users.
Progressive Tool Rollout: We can gradually expose endpoints to AI assistants by adding the mcp metadata flag. This lets us test AI interactions with less critical endpoints before exposing core business operations.
Context-Aware Permissions: We're working on permission rules that distinguish between human-initiated and AI-initiated requests. For example, an AI assistant might be allowed to read sensitive data to answer questions but not include it in generated reports.
The Bottom Line
Building parallel implementations for REST and MCP is unnecessary complexity that creates real problems. By generating MCP tools from ts-rest contracts and routing both interfaces through the same implementation, we've eliminated an entire category of bugs, security issues, and maintenance overhead.
Your API contracts already describe what your endpoints do. Why not use that information to automatically build AI tool interfaces that are guaranteed to stay in sync?
Come join us in finding faster and better ways to build our enterprise commerce AI product at StockApp!